
Federated Learning
Unseren Forschungsbereich "Federated Learning" kann man auch als "Verteiltes maschinelles Lernen" bezeichnen. Dieser ist ein zukunftsweisender Bereich, welcher sogar bereits in der Praxis angewendet wird. Im Bild ist ein kleines Beispiel abgebildet, welches das Zusammenspiel von drei Datenbesitzern und einem Service-Anbieter zeigt.
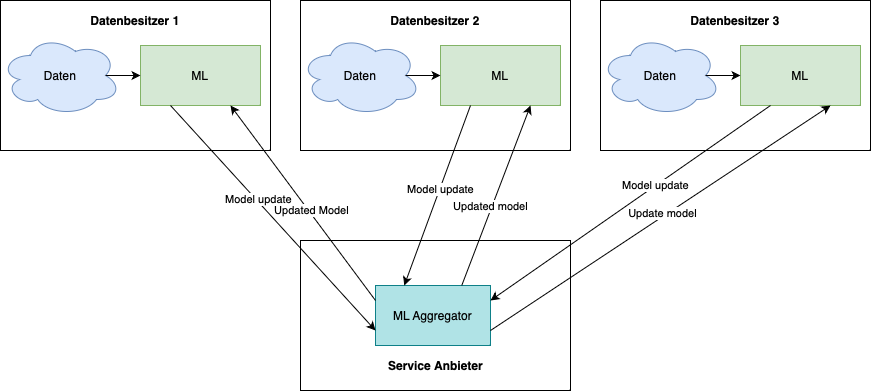
Was versteht man unter "Federated Learning"?
Ohne verteiltes maschinelles Lernen müssen die Daten, welche zum Lernen verwendet werden sollen, an einem Ort gesammelt werden, um sie gemeinsam zu verwenden. Das birgt hohe Sicherheitsrisiken und es können auch nicht immer alle Daten herausgegeben werden. Um trotzdem mit diesen Daten lernen zu können, wird das verteilte maschinelle Lernen angewandt. Anstatt Daten zu sammeln, hat jeder Datenbesitzer das Model zum maschinellen Lernen lokal. Die Rohdaten verlassen den Besitzer nicht, sondern es wird lokal gelernt und nur die darauf entstehenden "model updates" werden zu einem Service-Anbieter geschickt. Dieser betreibt einen ML-Aggregator, welcher die "model updates" aggregiert und ein daraus entstandenes "updated model" zu den Datenbesitzern zurückschickt. Mit diesem kann erneut lokal auf den Daten gelernt werden. Dieser Ablauf wird so lange wiederholt bis ein Abbruchkriterium erreicht ist.
Welche Vorteile liefert das Vorgehen?
Keiner der Datenbesitzer muss seine Daten herausgeben oder an einem Ort sammeln. Außerdem ist oft das verteilte Lernen effizienter, da die Daten bereits verteilt vorliegen und sofort genutzt werden können. Zudem kann das Modell zum Lernen auf kleineren Datensätzen angewendet werden.
Unsere aktuellen Forschungsthemen
- Homomorphe Verschlüsselung:
- Durch "Federated Learning" entstehen bereits einige Vorteile im Hinblick auf Datensouveränität und Datensicherheit, jedoch können durch die "model updates" immer noch Rückschlüsse auf die Original-Daten gezogen werden. Deshalb erweitern wir die Methode mit der homomorphen Verschlüsselung, welche ermöglicht auf verschlüsselten Daten zu arbeiten. Die "model updates" werden vor dem Verschicken aufseiten des Datenbesitzers verschlüsselt und werden anschließend im verschlüsselten Zustand aggregiert und erst beim Besitzer wieder entschlüsselt. Um das Schema auf das "Federated Learning" anzupassen, arbeiten wir mit spannenden Techniken wie dem "Shamir Secret Sharing" um nicht einen einheitlichen privaten Schlüssel verwenden zu müssen.
- Datenräume:
- Außerdem kombinieren wir den Ansatz mit verteilten und föderierten Datenräumen, um die daraus entstehenden Vorteile ebenfalls anzuwenden. Dabei wird vor allem die Selbstbestimmtheit und somit die Datensouveränität gesichert. Jeder Teilnehmende wird durch einen Connector ebenfalls Teilnehmer am Datenraum und kann selbst bestimmen, wann und unter welchen Konditionen seine Daten verschickt und verwendet werden.
Dabei handelt es sich nur um einen kleinen Einblick. Wir freuen uns, Informatik-Studierende, die an diesen spannenden Forschungsthemen interessiert sind, auf unserer Website zu begrüßen. Wenn Sie weiteres Interesse an unserer Forschung haben oder mehr erfahren möchten, zögern Sie nicht, uns zu kontaktieren.